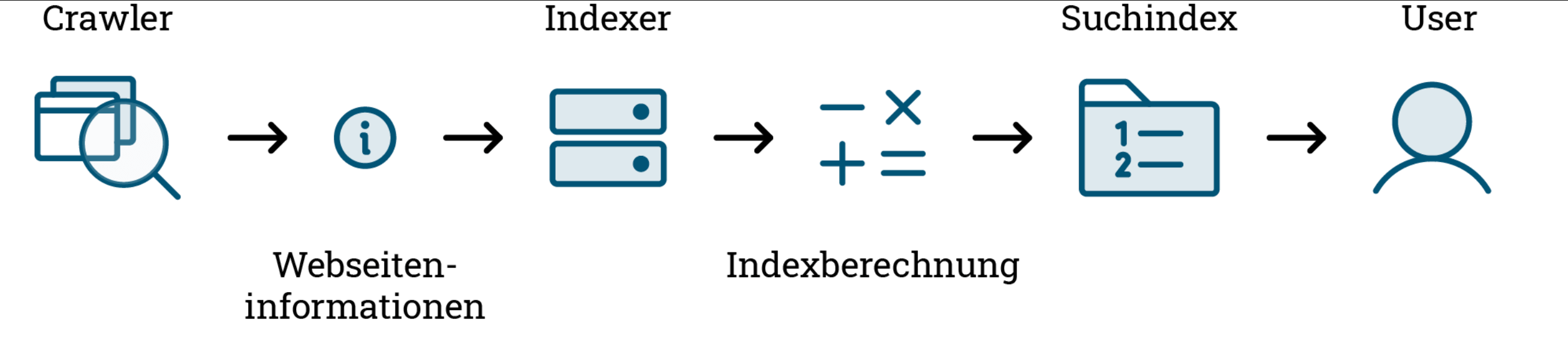
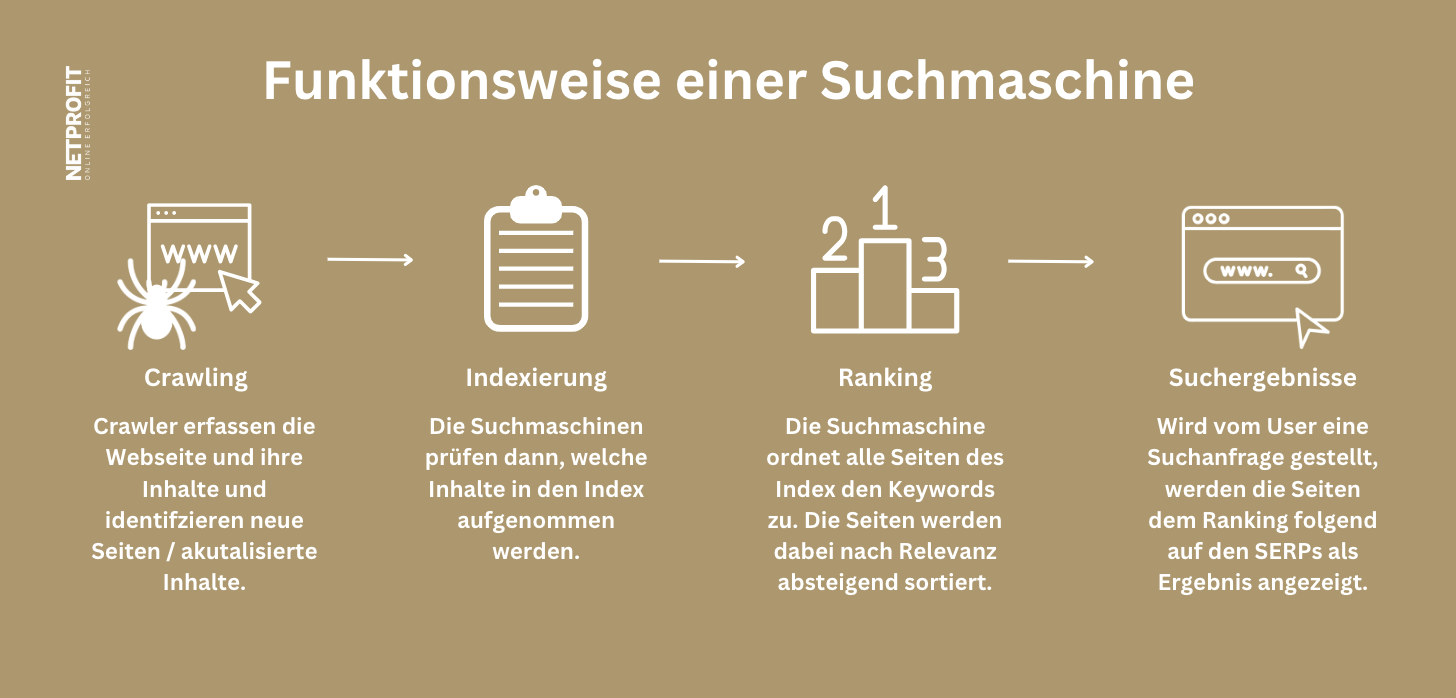
Der Crawling-Prozess ist entscheidend für SEO, da er sicherstellt, dass Suchmaschinen die Inhalte einer Webseite erkennen und indexieren können. Ohne eine effiziente Indexierung durch Crawler würden die Webseiten nicht in den Suchergebnissen erscheinen und wären für potenzielle Besucher schwer zu finden.
Daher ist eine SEO-optimierte Webseite darauf ausgerichtet, Crawlern den Zugriff auf relevante und gut strukturierte Inhalte zu ermöglichen. Durch die Implementierung von SEO-Strategien wie die Verwendung von relevanten Keywords, die Optimierung der Seitenstruktur und die Verbesserung der Ladezeiten kann die Sichtbarkeit einer Webseite in den Suchmaschinenergebnissen erhöht werden, was wiederum den Crawlern hilft, die Webseite zu erkennen und für Nutzer sichtbar zu machen.